|
This week, the Future of Life Institute (FLI) issued an open letter calling for technology businesses and Artificial Intelligence (AI) research laboratories to halt any work on any AI more advanced than GP4. The letter, signed by some famous names, warns about the dangers advanced AI can pose without appropriate governance and quotes from the Asilomar AI principles issued in 2017. While well-intentioned in warning about the dangers posed by advanced AI, the letter is a bit premature as their target, the Large Language Models (LLMs), are no closer to Artificial General Intelligence (AGI) than we are closer to humans settling on Mars. Let me explain why. If we consider human intelligence the benchmark for how AI systems are modelled, we must first understand how humans learn. This process is succinctly captured in the below illustration (Greenleaf & Wells-Papanek, 2005). 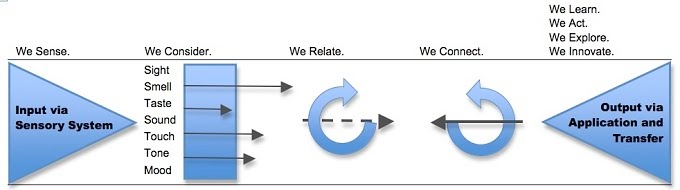 Here we can observe that we utilise our senses to draw upon inputs from the environment and then utilise our cognitive process to relate the information to previous memories or learning and then apply it to the current situation and act accordingly. While the actual process in the human brain, incorporating short-term and long-term memories and the versatile cognitive abilities of different parts of the brain, is more complex, it is essential to note that the key steps are the 'relation' and 'connection' to 'memories' or 'existing knowledge, leading to insights as illustrated in the below figure (Albers et al., 2012). 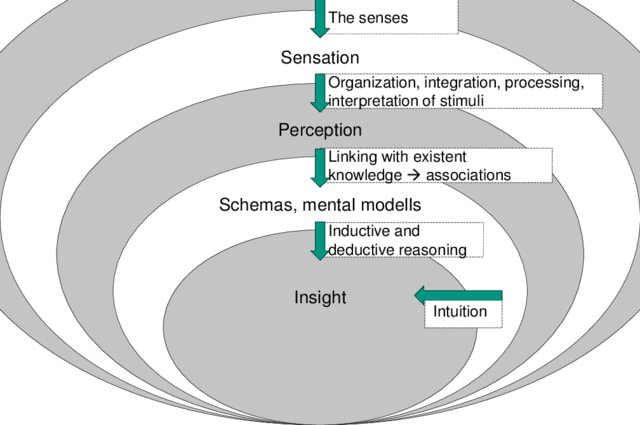 Now let's look at how LLMs operate. These models process data by breaking it into smaller, more manageable tokens. These tokens are then converted into numerical representations that the model can work with using tokenization. Once the data has been tokenized, the model uses complex mathematical functions and algorithms to analyze and understand the relationships between the tokens. This process is called training, and it involves feeding the model large amounts of data and adjusting its internal parameters until it can accurately predict the next token in a sequence, given a certain input. When the model is presented with new data, it uses its trained parameters to generate outputs by predicting the most likely sequence of tokens following the input. This output can take many forms, depending on the application - for example, it could be a text response to a user's query or a summary of a longer text. Overall, large language models use a combination of statistical analysis, machine learning, and natural language processing techniques to process data and generate outputs that mimic human language. This process is illustrated in this representation of GPT4 architecture, where in addition to text, images are utilised as input (source: TheAIEdge.io) 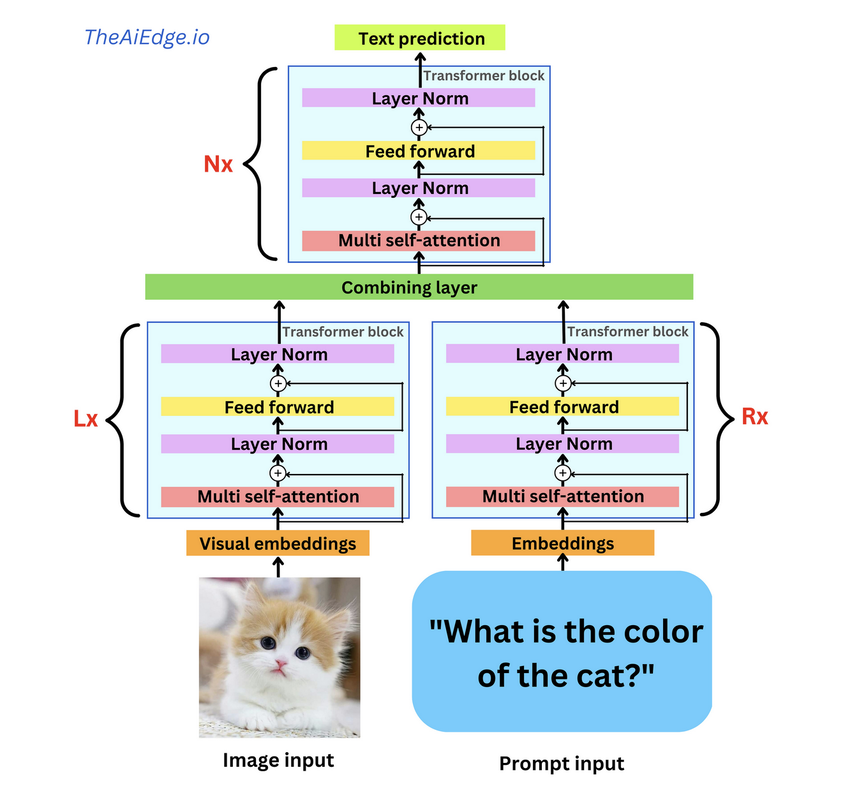 AGI refers to the ability of an AI system to perform any intellectual task that a human can. While language is an essential aspect of human intelligence, only one component of the broader spectrum of capabilities defines AGI. In other words, language models may be proficient at language tasks but lack the versatility and flexibility to perform tasks outside their training data.
One of the primary limitations of large language models is their lack of generalization. These models are trained on large amounts of data and can generate impressive results within their trained domain. However, they struggle to apply this knowledge to new and unseen tasks. This limitation is because language models are trained through supervised learning, giving them a specific task and corresponding data to learn from. As a result, these models cannot reason or make decisions based on broader contexts. Another limitation of language models is their lack of common sense. While these models can generate coherent text and answer some basic factual questions, they cannot understand the world as humans do. For instance, they may be able to generate a recipe for a cake, but they cannot understand the implications of adding too much salt or sugar to the recipe. Furthermore, language models cannot interact with the physical world. AGI systems must be able to interact with the world as humans do. They must be able to perceive their surroundings, reason about the objects and people around them, and take appropriate actions. Language models are limited to processing text and cannot interact with the world meaningfully. Importantly, language models cannot retain memories (whether short-term or long-term), which are so essential to human learning and intelligence. So an autoregressive approach that language models adopt by analysing their training data is not a substitute for human learning. The road to AGI for large language developers is to create larger models supported by significant computational resources. These models are not just complex in their parameters but are environmentally unfriendly. Critically, they are black-box models, which even currently available explainable AI frameworks cannot scrutinise. With some LLM developers indicating they will not make the architecture and training process available to the public, it amounts to a selfish move and a scary development for the general public and the AI community. LLMs can be used to generate text that is designed to mislead or deceive people. This could spread false information, manipulate public opinion, or incite violence. LLMs can be used to create deep fakes that are very realistic, which could be used to damage someone's reputation or spread misinformation. This could lead to job losses and economic disruption. It could also lead to a concentration of power in the hands of a few companies that control the LLMs. LLMs are trained on data collected from the real world, which can contain biases. If these biases are not identified and addressed, they could be embedded in the LLMs and lead to biased systems against certain groups of people. LLMs are complex systems that are difficult to understand and secure. This makes them vulnerable to attacks by malicious actors. These issues may have led to the aforementioned letter, but to assume that LLMs are the next step to AGI is incomprehensible. First, LLMs cannot understand the meaning of language in the same way humans do. They can generate text that is grammatically correct and factually accurate, but they do not have the same level of understanding of the world as humans. Second, LLMs are not able to generalize their knowledge to new situations. They are trained on a specific set of data and can only perform tasks they have been trained on. Third, LLMs cannot learn and adapt to new information in the same way humans do. They are trained on a fixed set of data and cannot learn new things without being explicitly programmed to do so. Does intelligence have to be modelled regarding how humans learn? Couldn't alternative models of intelligence be as well as useful? I have argued for this in the past, but is this something we want? If we can't comprehend how an intelligence model works, it is a recipe for disaster if we can't control it anymore (read AI singularity). The most practical and human-friendly approach is developing intelligence models that align with human learning. While daunting and perhaps not linear, this path presents a more benign approach vis a vis explainability, transparency, humane, and climate-friendly principles.
0 Comments
Leave a Reply. |
AuthorHealth System Academic Archives
December 2023
Categories |
 RSS Feed
RSS Feed